publications
My publications in reversed chronological order.
2025
-
VLOGGER: Multimodal Diffusion for Embodied Avatar SynthesisCorona, Enric, Zanfir, Andrei, Bazavan, Eduard Gabriel, Kolotouros, Nikos, Alldieck, Thiemo, and Sminchisescu, CristianIn CVPR 2025

2024
-
Instant 3D Human Avatar Generation using Image Diffusion ModelsKolotouros, Nikos, Alldieck, Thiemo, Corona, Enric, Bazavan, Eduard Gabriel, and Sminchisescu, CristianIn European Conference on Computer Vision (ECCV) 2024

2023
-
DreamHuman: Animatable 3D Avatars from TextKolotouros, Nikos, Alldieck, Thiemo, Zanfir, Andrei, Bazavan, Eduard Gabriel, Fieraru, Mihai, and Sminchisescu, CristianIn NeurIPS 2023
We present DreamHuman, a method to generate realistic animatable 3D human avatar models solely from textual descriptions. Recent text-to-3D methods have made considerable strides in generation, but are still lacking in important aspects. Control and often spatial resolution remain limited, existing methods produce fixed rather than animated 3D human models, and anthropometric consistency for complex structures like people remains a challenge. DreamHuman connects large text-to-image synthesis models, neural radiance fields, and statistical human body models in a novel modeling and optimization framework. This makes it possible to generate dynamic 3D human avatars with high-quality textures and learned, instance-specific, surface deformations. We demonstrate that our method is capable to generate a wide variety of animatable, realistic 3D human models from text. Our 3D models have diverse appearance, clothing, skin tones and body shapes, and significantly outperform both generic text-to-3D approaches and previous text-based 3D avatar generators in visual fidelity.
@inproceedings{kolotouros2023dreamhuman, title = {DreamHuman: Animatable 3D Avatars from Text}, author = {Kolotouros, Nikos and Alldieck, Thiemo and Zanfir, Andrei and Bazavan, Eduard Gabriel and Fieraru, Mihai and Sminchisescu, Cristian}, booktitle = {NeurIPS}, year = {2023}, website = {https://dream-human.github.io}, pdf = {https://openreview.net/pdf?id=rheCTpRrxI}, selected = {true}, bibtex_show = {true}, abbr = {dreamhuman} }


2021
-
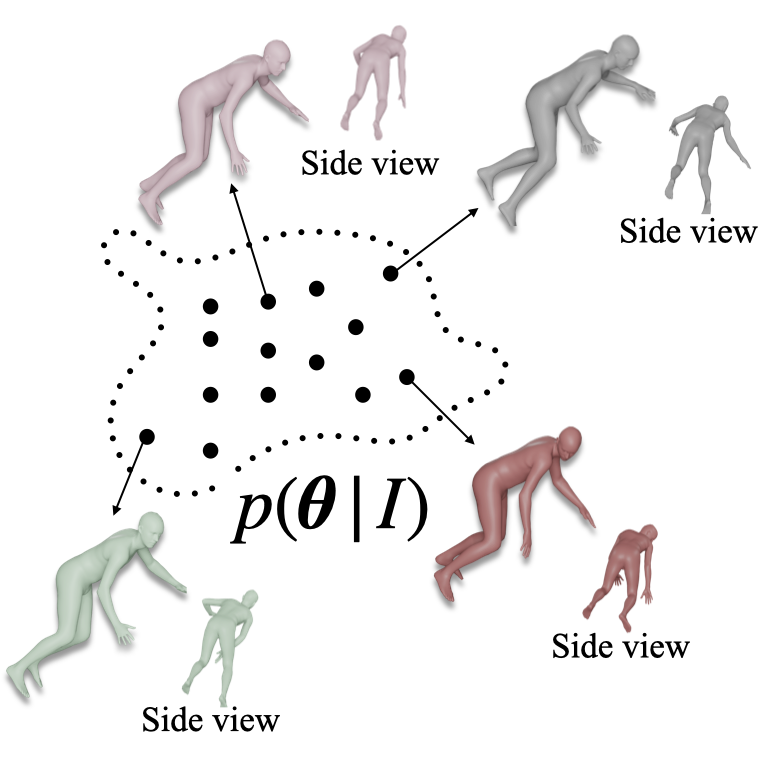
Probabilistic Modeling for Human Mesh RecoveryIn ICCV 2021
This paper focuses on the problem of 3D human reconstruction from 2D evidence. Although this is an inherently ambiguous problem, the majority of recent works avoid the uncertainty modeling and typically regress a single estimate for a given input. In contrast to that, in this work, we propose to embrace the reconstruction ambiguity and we recast the problem as learning a mapping from the input to a distribution of plausible 3D poses. Our approach is based on the normalizing flows model and offers a series of advantages. For conventional applications, where a single 3D estimate is required, our formulation allows for efficient mode computation. Using the mode leads to performance that is comparable with the state of the art among deterministic unimodal regression models. Simultaneously, since we have access to the likelihood of each sample, we demonstrate that our model is useful in a series of downstream tasks, where we leverage the probabilistic nature of the prediction as a tool for more accurate estimation. These tasks include reconstruction from multiple uncalibrated views, as well as human model fitting, where our model acts as a powerful image-based prior for mesh recovery. Our results validate the importance of probabilistic modeling, and indicate state-of-the-art performance across a variety of settings. Code and models are available at: https://www.nikoskolot.com/projects/prohmr.
@inproceedings{kolotouros2021prohmr, title = {Probabilistic Modeling for Human Mesh Recovery}, author = {Kolotouros, Nikos and Pavlakos, Georgios and Jayaraman, Dinesh and Daniilidis, Kostas}, booktitle = {ICCV}, year = {2021}, website = {/projects/prohmr/}, pdf = {https://arxiv.org/pdf/2108.11944}, code = {https://github.com/nkolot/ProHMR}, supp = {https://openaccess.thecvf.com/content/ICCV2021/supplemental/Kolotouros_Probabilistic_Modeling_for_ICCV_2021_supplemental.pdf}, selected = {true}, bibtex_show = {true}, abbr = {prohmr}, interview = {https://www.rsipvision.com/ComputerVisionNews-2021November/28/} } -
Birds of a Feather: Capturing Avian Shape Models from ImagesIn CVPR 2021
Automated capture of animal pose is transforming how we study neuroscience and social behavior. Movements carry important social cues, but current methods are not able to robustly estimate pose and shape of animals, particularly for social animals such as birds, which are often occluded by each other and objects in the environment. To address this problem, we first introduce a model and multi-view optimization approach, which we use to capture the unique shape and pose space displayed by live birds. We then introduce a pipeline and experiments for keypoint, mask, pose, and shape regression that recovers accurate avian postures from single views. Finally, we provide extensive multi-view keypoint and mask annotations collected from a group of 15 social birds housed together in an outdoor aviary.
@inproceedings{wang2021aves, title = {Birds of a Feather: Capturing Avian Shape Models from Images}, author = {Wang, Yufu and Kolotouros, Nikos and Daniilidis, Kostas and Badger, Marc}, booktitle = {CVPR}, year = {2021}, website = {https://yufu-wang.github.io/aves/}, pdf = {https://arxiv.org/pdf/2105.09396}, code = {https://github.com/yufu-wang/aves}, supp = {https://marcbadger.github.io/avian-mesh/files/3d_birds_singleview-supp.pdf}, bibtex_show = {true}, abbr = {aves} }


2020
-
3D Bird Reconstruction: a Dataset, Model, and Shape Recovery from a Single ViewBadger, Marc, Wang, Yufu, Modh, Adarsh, Perkes, Ammon, Kolotouros, Nikos, Pfrommer, Bernd, Schmidt, Marc, and Daniilidis, KostasIn ECCV 2020
Automated capture of animal pose is transforming how we study neuroscience and social behavior. Movements carry important social cues, but current methods are not able to robustly estimate pose and shape of animals, particularly for social animals such as birds, which are often occluded by each other and objects in the environment. To address this problem, we first introduce a model and multi-view optimization approach, which we use to capture the unique shape and pose space displayed by live birds. We then introduce a pipeline and experiments for keypoint, mask, pose, and shape regression that recovers accurate avian postures from single views. Finally, we provide extensive multi-view keypoint and mask annotations collected from a group of 15 social birds housed together in an outdoor aviary.
@inproceedings{badger2020, title = {{3D} Bird Reconstruction: a Dataset, Model, and Shape Recovery from a Single View}, author = {Badger, Marc and Wang, Yufu and Modh, Adarsh and Perkes, Ammon and Kolotouros, Nikos and Pfrommer, Bernd and Schmidt, Marc and Daniilidis, Kostas}, booktitle = {ECCV}, year = {2020}, website = {https://marcbadger.github.io/avian-mesh/}, pdf = {https://arxiv.org/abs/2008.06133}, code = {https://github.com/marcbadger/avian-mesh}, supp = {https://marcbadger.github.io/avian-mesh/files/3d_birds_singleview-supp.pdf}, bibtex_show = {true}, abbr = {3dbird} } -
Coherent Reconstruction of Multiple Humans from A Single ImageIn CVPR 2020
In this work, we address the problem of multi-person 3D pose estimation from a single image. A typical regression approach in the top-down setting of this problem would first detect all humans and then reconstruct each one of them independently. However, this type of predic- tion suffers from incoherent results, e.g., interpenetration and inconsistent depth ordering between the people in the scene. Our goal is to train a single network that learns to avoid these problems and generate a coherent 3D reconstruction of all the humans in the scene. To this end, a key design choice is the incorporation of the SMPL parametric body model in our top-down framework, which enables the use of two novel losses. First, a distance field-based collision loss penalizes interpenetration among the reconstructed people. Second, a depth ordering-aware loss reasons about occlusions and promotes a depth ordering of people that leads to a rendering which is consistent with the annotated instance segmentation. This provides depth supervision signals to the network, even if the image has no explicit 3D annotations. The experiments show that our approach outperforms previous methods on standard 3D pose benchmarks, while our proposed losses en- able more coherent reconstruction in natural images.
@inproceedings{jiang2020multiperson, title = {Coherent Reconstruction of Multiple Humans from A Single Image}, author = {Jiang, Wen* and Kolotouros, Nikos* and Pavlakos, Georgios and Zhou, Xiaowei and Daniilidis, Kostas}, booktitle = {CVPR}, year = {2020}, website = {https://jiangwenpl.github.io/multiperson/}, pdf = {https://arxiv.org/pdf/2006.08586.pdf}, code = {https://github.com/JiangWenPL/multiperson}, supp = {https://jiangwenpl.github.io/multiperson/files/multiperson-supp.pdf}, selected = {true}, bibtex_show = {true}, abbr = {multiperson} }



2019
-
Learning to Reconstruct 3D Human Pose and Shape via Model-fitting in the LoopIn ICCV 2019
Model-based human pose estimation is currently approached through two different paradigms. Optimization-based methods fit a parametric body model to 2D observations in an iterative manner, leading to accurate image-model alignments, but are often slow and sensitive to the initialization. In contrast, regression-based methods, that use a deep network to directly estimate the model parameters from pixels, tend to provide reasonable, but not pixel accurate, results while requiring huge amounts of supervision. In this work, instead of investigating which approach is better, our key insight is that the two paradigms can form a strong collaboration. A reasonable, directly regressed estimate from the network can initialize the iterative optimization making the fitting faster and more accurate. Similarly, a pixel accurate fit from iterative optimization can act as strong supervision for the network. This is the core of our proposed approach SPIN (SMPL oPtimization IN the loop). The deep network initializes an iterative optimization routine that fits the body model to 2D joints within the training loop, and the fitted estimate is subsequently used to supervise the network. Our approach is self-improving by nature, since better network estimates can lead the optimization to better solutions, while more accurate optimization fits provide better supervision for the network. We demonstrate the effectiveness of our approach in different settings, where 3D ground truth is scarce, or not available, and we consistently outperform the state-of-the-art model-based pose estimation approaches by significant margins.
@inproceedings{kolotouros2019spin, title = {Learning to Reconstruct 3D Human Pose and Shape via Model-fitting in the Loop}, author = {Kolotouros, Nikos* and Pavlakos, Georgios* and Black, Michael J. and Daniilidis, Kostas}, booktitle = {ICCV}, year = {2019}, website = {/projects/spin/}, pdf = {https://arxiv.org/abs/1909.12828}, code = {https://github.com/nkolot/SPIN}, supp = {https://openaccess.thecvf.com/content_ICCV_2019/supplemental/Kolotouros_Learning_to_Reconstruct_ICCV_2019_supplemental.pdf}, selected = {true}, bibtex_show = {true}, abbr = {spin} } -
TexturePose: Supervising Human Mesh Estimation with Texture ConsistencyPavlakos, Georgios*, Kolotouros, Nikos*, and Daniilidis, KostasIn ICCV 2019
This work addresses the problem of model-based human pose estimation. Recent approaches have made significant progress towards regressing the parameters of parametric human body models directly from images. Because of the absence of images with 3D shape ground truth, relevant approaches rely on 2D annotations or sophisticated architecture designs. In this work, we advocate that there are more cues we can leverage, which are available for free in natural images, i.e., without getting more annotations, or modifying the network architecture. We propose a natural form of supervision, that capitalizes on the appearance constancy of a person among different frames (or viewpoints). This seemingly insignificant and often overlooked cue goes a long way for model-based pose estimation. The parametric model we employ allows us to compute a texture map for each frame. Assuming that the texture of the person does not change dramatically between frames, we can apply a novel texture consistency loss, which enforces that each point in the texture map has the same texture value across all frames. Since the texture is transferred in this common texture map space, no camera motion computation is necessary, or even an assumption of smoothness among frames. This makes our proposed supervision applicable in a variety of settings, ranging from monocular video, to multi-view images. We benchmark our approach against strong baselines that require the same or even more annotations that we do and we consistently outperform them. Simultaneously, we achieve state-of-the-art results among model-based pose estimation approaches in different benchmarks
@inproceedings{pavlakos2019texturepose, title = {Texture{P}ose: Supervising Human Mesh Estimation with Texture Consistency}, author = {Pavlakos, Georgios* and Kolotouros, Nikos* and Daniilidis, Kostas}, booktitle = {ICCV}, year = {2019}, website = {https://geopavlakos.github.io/projects/texturepose}, pdf = {https://arxiv.org/pdf/1910.11322.pdf}, code = {https://github.com/geopavlakos/TexturePose}, supp = {https://geopavlakos.github.io/projects/texturepose/files/texturepose-supp.pdf}, selected = {true}, bibtex_show = {true}, abbr = {texturepose} } -
Convolutional Mesh Regression for Single-Image Human Shape ReconstructionKolotouros, Nikos, Pavlakos, Georgios, and Daniilidis, KostasIn CVPR 2019
This paper addresses the problem of 3D human pose and shape estimation from a single image. Previous approaches consider a parametric model of the human body, SMPL, and attempt to regress the model parameters that give rise to a mesh consistent with image evidence. This parameter regression has been a very challenging task, with model-based approaches underperforming compared to nonparametric solutions in terms of pose estimation. In our work, we propose to relax this heavy reliance on the model’s parameter space. We still retain the topology of the SMPL template mesh, but instead of predicting model parameters, we directly regress the 3D location of the mesh vertices. This is a heavy task for a typical network, but our key insight is that the regression becomes significantly easier using a Graph-CNN. This architecture allows us to explicitly encode the template mesh structure within the network and leverage the spatial locality the mesh has to offer. Image-based features are attached to the mesh vertices and the Graph-CNN is responsible to process them on the mesh structure, while the regression target for each vertex is its 3D location. Having recovered the complete 3D geometry of the mesh, if we still require a specific model parametrization, this can be reliably regressed from the vertices locations. We demonstrate the flexibility and the effectiveness of our proposed graph-based mesh regression by attaching different types of features on the mesh vertices. In all cases, we outperform the comparable baselines relying on model parameter regression, while we also achieve state-of-the-art results among model-based pose estimation approaches.
@inproceedings{kolotouros2019cmr, author = {Kolotouros, Nikos and Pavlakos, Georgios and Daniilidis, Kostas}, title = {Convolutional Mesh Regression for Single-Image Human Shape Reconstruction}, booktitle = {CVPR}, year = {2019}, website = {/projects/cmr/}, pdf = {http://arxiv.org/pdf/1905.03244.pdf}, code = {https://github.com/nkolot/GraphCMR/}, supp = {https://www.seas.upenn.edu/~nkolot/projects/cmr/files/cmr-supp.pdf}, selected = {true}, bibtex_show = {true}, abbr = {cmr} }




