Method
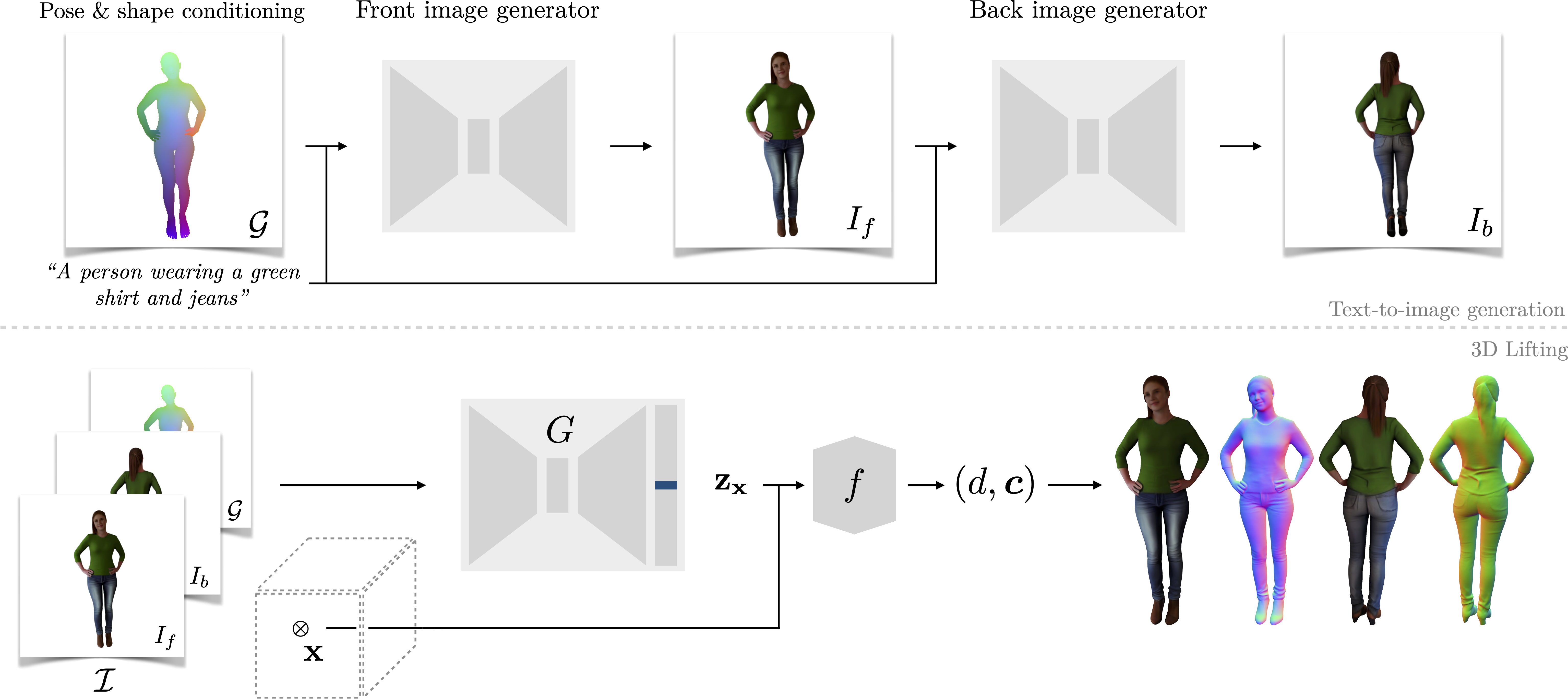
AvatarPopUp builds on the capacity of text-to-image models to generate highly detailed and diverse input images.
First, a Latent Diffusion network takes a text prompt and a target body pose and shape G,
and generates a highly detailed front image of a person.
Next, a second network generates a consistent back view in the same pose and clothing.
We then perform pixel-aligned 3D reconstruction given the generated back/front views/images and/or a given 3D body pose and shape G.
This decoupling enables the generation of 3D avatars from either text or a single image.


